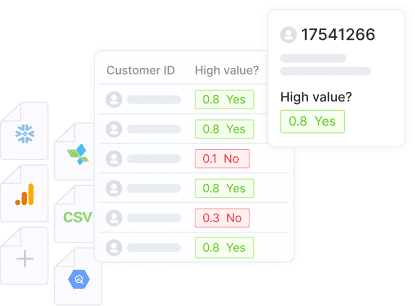
Discover the power of data science automation with AI handling tasks from data prep to model deployment. Speed up and streamline workflows.

April 22, 2024
April 22, 2024
April 8, 2024
March 28, 2024
April 22, 2024
April 22, 2024
March 28, 2024
March 20, 2024
April 19, 2024
April 16, 2024
April 15, 2024
April 4, 2024
April 2, 2024
April 2, 2024
April 1, 2024
March 15, 2024
March 15, 2024
March 14, 2024
March 13, 2024
March 12, 2024
March 11, 2024
March 10, 2024
March 8, 2024
March 7, 2024
March 6, 2024
March 5, 2024
March 5, 2024
March 4, 2024
March 4, 2024
March 3, 2024
March 2, 2024
March 2, 2024
February 29, 2024
February 28, 2024
February 26, 2024
February 26, 2024
February 23, 2024
February 23, 2024
February 22, 2024
February 21, 2024
February 20, 2024
February 19, 2024
February 17, 2024
February 16, 2024
February 16, 2024
February 16, 2024
February 15, 2024
February 15, 2024
February 14, 2024
February 14, 2024
January 31, 2024
January 30, 2024
January 30, 2024
January 29, 2024
January 28, 2024
January 27, 2024
January 24, 2024
January 23, 2024
January 22, 2024
January 17, 2024
January 17, 2024
January 16, 2024
January 16, 2024
January 11, 2024
January 9, 2024
January 8, 2024
January 7, 2024
January 7, 2024
January 6, 2024
January 4, 2024
January 4, 2024
January 3, 2024
December 28, 2023
December 28, 2023
December 23, 2023
December 21, 2023
December 18, 2023
December 15, 2023
December 14, 2023
December 8, 2023
December 8, 2023
December 8, 2023
December 7, 2023
December 6, 2023
December 6, 2023
December 2, 2023
December 1, 2023
December 1, 2023
December 1, 2023
December 1, 2023
November 30, 2023
November 30, 2023
November 30, 2023
November 30, 2023
November 29, 2023
November 29, 2023
November 29, 2023
November 21, 2023
November 21, 2023
November 20, 2023
November 20, 2023
November 19, 2023
November 19, 2023
November 17, 2023
November 17, 2023
November 16, 2023
November 15, 2023
November 15, 2023
November 15, 2023
November 13, 2023
November 13, 2023
November 12, 2023
November 11, 2023
November 11, 2023
November 11, 2023
November 10, 2023
November 10, 2023
November 9, 2023
November 8, 2023
November 7, 2023
November 7, 2023
November 6, 2023
November 6, 2023
November 6, 2023
November 2, 2023
November 2, 2023
November 1, 2023
November 1, 2023
November 1, 2023
October 31, 2023
October 12, 2023
October 9, 2023
September 10, 2023
September 10, 2023
August 30, 2023
August 27, 2023
August 26, 2023
August 26, 2023
August 25, 2023
August 22, 2023
August 3, 2023
August 2, 2023
July 30, 2023
July 19, 2023
July 12, 2023
July 3, 2023
June 30, 2023
June 7, 2023
June 5, 2023
May 31, 2023
May 30, 2023
May 24, 2023
May 18, 2023
May 16, 2023
May 9, 2023
May 4, 2023
May 3, 2023
April 19, 2023
April 17, 2023
April 11, 2023
April 10, 2023
April 6, 2023
April 3, 2023
April 2, 2023
April 2, 2023
March 30, 2023
March 23, 2023
March 20, 2023
March 2, 2023
February 13, 2023
February 9, 2023
February 2, 2023
January 31, 2023
January 29, 2023
January 27, 2023
January 24, 2023
January 17, 2023
January 10, 2023
January 4, 2023
December 19, 2022
December 13, 2022
December 6, 2022
November 21, 2022
November 17, 2022
November 10, 2022
November 8, 2022
November 3, 2022
October 27, 2022
October 19, 2022
October 17, 2022
October 12, 2022
October 12, 2022
September 14, 2022
September 12, 2022
September 6, 2022
September 6, 2022
August 31, 2022
August 30, 2022
August 25, 2022
August 23, 2022
August 23, 2022
August 19, 2022
August 18, 2022
August 15, 2022
August 9, 2022
July 25, 2022
July 25, 2022
July 21, 2022
July 20, 2022
July 15, 2022
July 14, 2022
June 28, 2022
June 21, 2022
June 15, 2022
June 1, 2022
May 24, 2022
May 24, 2022
May 23, 2022
April 28, 2022
April 28, 2022
April 24, 2022
April 23, 2022
April 23, 2022
April 23, 2022
April 23, 2022
April 23, 2022
April 23, 2022
April 14, 2022
April 7, 2022
March 23, 2022
February 22, 2022
February 2, 2022
December 28, 2021
November 29, 2021
March 30, 2021
February 15, 2021