
Imagine the impact of underreporting pandemic cases due to a lack of awareness about Excel spreadsheet capabilities. Or an HR recruiting system that only recommends male job candidates. Or your company overpaying hundreds of millions of dollars in inventory because of a bad algorithm.
Clearly, data and analytics mistakes happen – sometimes on a huge scale, and sometimes with serious repercussions. From compromising decision-making to undermining strategic planning and organizational success, the stakes are high.
In this blog post, we explore six common mistakes that can lead to flawed data analysis, and then share insights on how you can recover from such mistakes and avoid them in the future.
Common sources of mistakes in data analytics
The world of data analytics is evolving rapidly. And as businesses increasingly rely on insights to drive informed decision-making, data analysts are becoming more and more indispensable.
But even if you’re a seasoned analyst, there are many challenges that come with the territory – there’s a mistake waiting for you around every corner. But we know that you are more than capable of handling this challenge, especially when you keep these six potential pitfalls in mind:
1. Misunderstanding of data and metrics
Misunderstanding can come in many different forms, such as unclear definitions of variables, a lack of alignment around data objects, not knowing where data is coming from, and not knowing what types of data are required.
For example, different teams within an organization may have different definitions of churn. Say a data analyst builds a churn model that predicts the likelihood of customers to not make a purchase within 90 days. The resulting predictions may be accurate, but they’ll be unusable if the relevant business team defines churn by not making a purchase within 180 days.
Or, you can take the simple example of an integer data type being used instead of a float data type. This little error will result in missed decimal points that could have a huge financial impact.
2. Poor data collection and validation
The foundation of any data analysis is the quality and integrity of the data itself. Insufficient or unreliable data-collection methods can introduce inaccuracies from the start, leading to skewed conclusions and faulty insights.
Common problems include insufficient data cleansing, a lack of validation techniques, and inconsistencies in the data itself. For example, if you fail to check for proper formatting or outliers in your data, this can have disastrous effects on your analysis.
3. Incorrect SQL queries
It’s crucial to write valid SQL queries that suit your specific data analysis and adhere to best practices. Using bad queries is a sure way to achieve inaccurate or misleading results. Worse yet, they can slow down system performance, compromise data integrity, and even pose security threats through SQL injection attacks.
Even if your queries are technically correct, but aren’t relevant to the business question being asked and don’t pull the correct data, they won’t get you very far.
4. Not accounting for context
Context is key to extracting meaningful insights from data and gauging their significance. Without a thorough understanding of your data’s context and the scope of analysis, you can easily draw conclusions that fail to account for the bigger picture.
For example, imagine you calculated the average income for each age segment among your customers. But you failed to consider factors like educational status or employment. Seeing a lower average income for a particular age group may lead to a misrepresentation of their actual financial situation. For example, maybe the lower-income group happens to have a higher proportion of students.
Ignoring context can result in incorrect or inaccurate conclusions, and ultimately drive misguided business decisions.
5. Introducing bias and assumptions
Human bias can subtly yet dramatically influence the entire data analytics process, from selecting variables to interpreting the results.
A classic example of this is selection bias, which occurs when the data used for analysis is not a representative sample of the entire population or target group. This bias can significantly impact the validity of your analysis and cause misleading conclusions.
Preconceived assumptions can cloud objectivity and lead to conclusions that align with expectations rather than empirical evidence. For example, you can imagine how a person’s bias may lead them to unintentionally confuse correlation with causation. So here are some other pitfalls to watch out for: seeking data that confirms intuition, not being open to new or unexpected insights from data, and jumping to conclusions.
6. Lack of clear communication
Even the most accurate data analysis is useless if it can’t be effectively communicated to stakeholders. Your ability to convey complex findings in a clear and understandable manner is essential to create meaningful impact in your role, and to ensure your results are interpreted correctly.
This calls for the ability to use language that resonates with business stakeholders, using effective data visualization techniques, and being able to tell stories through data. By becoming proficient in data communication, you can bridge the gap between raw data and actionable insights, and empower decision-makers to make well-informed choices that drive positive outcomes.
If you’re looking for more examples of mistakes in data analysis, here’s another article we loved.
What should you do if you’ve made a mistake?
Once you realize you’ve made a mistake, and that mistake has already been passed onto other parties or found its way into other tools or processes, it’s important to act responsibly and take immediate steps to rectify the situation.
The first step is to acknowledge and accept responsibility for your error. Trying to hide or ignore it may only exacerbate the situation and lead to more significant issues down the line. Taking ownership of your mistakes shows professionalism and a commitment to ensuring the accuracy and integrity of your work.
It’s likely that you’ll need to inform your supervisor or manager. It may be unpleasant, but when it comes to business and decision-making, transparency is vital. By reporting your mistakes to higher-ups, you’ll enable them to take appropriate action and make decisions based on the information they do have. They might not love it, but they’ll appreciate it.
At this point, you should begin to analyze the root cause of the mistake. Understanding how and why it occurred is crucial for preventing similar issues in the future. This will allow you to implement corrective measures that improve the data analysis process and prevent such errors from being repeated in the future.
Lastly, you should treat the experience as a learning opportunity. Mistakes are a natural part of any professional journey, and learning from what went wrong is an opportunity to grow and develop your skills.
What to do when you’ve made a mistake in your data analysis
- Acknowledge and accept responsibility
- Inform your supervisor or manager
- Analyze the root cause
- Learn from the experience
How to avoid providing incorrect insights
There are countless ways mistakes can happen in data analytics – and thus, countless ways to prevent and correct them.
Although this article is focused more on identifying problems than providing solutions, here are some basic strategies you can use to minimize errors and make your insights more reliable:
- Clarify business needs before getting started with a project. This will provide relevant context for the data and help ensure your insights will be of use.
- Make sure you’re aligned on project parameters, data definitions, what data is required, and where it’s coming from.
- Review the data for accuracy and reliability; this will provide a robust groundwork for your analysis and support the credibility of your findings.
- Use exploratory data analysis and visualizations to better understand data and spot potential issues before diving into an analysis (e.g. outliers, skewed populations, missing data).
- Take steps to recognize and address potential bias so you can control for factors that may affect outcomes.
- Perform regular SQL code reviews and use parameterized queries whenever possible.
- Document your processes. This will help you retrace your steps should an error occur.
- Encourage peer review by seeking out feedback and collaboration.
- Double-check your analysis. If something looks too perfect, there’s a good chance something is wrong.
- Consider formulating and testing hypotheses that would invalidate the conclusions you have already reached.
By following these general guidelines, you can steer clear of common pitfalls and create insights that provide a strong foundation for informed and accurate decision-making.
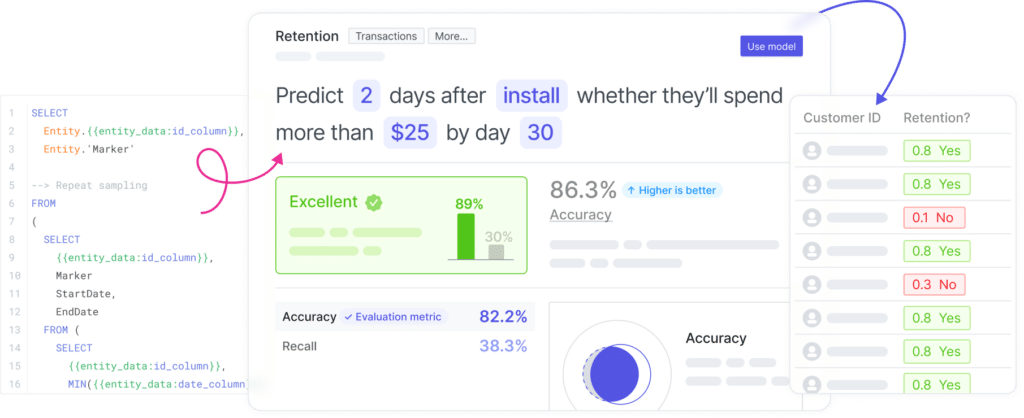
How automated predictive analytics prevents mistakes
As data becomes the primary driver behind decision-making processes, avoiding mistakes in your analyses becomes even more paramount. If you’re looking to elevate the quality of your work and contribute to your company’s success, you’ll want to learn about automated predictive analytics.
Predictive analytics involves the use of machine learning algorithms to analyze data and make predictions about future outcomes. Normally, this is a specialized and labor-intensive process that calls for a significant amount of data pre-processing and machine-learning expertise. In spite of its awesome potential, it is extremely time-consuming and error-prone, and typically requires the experience of a highly skilled data scientist or engineer.
But now, there’s a new crop of platforms that automate predictive analytics, using AI to explore and test a wide range of algorithms in order to find the best for your data. These platforms streamline the most complex and laborious processes, such as data preparation, feature engineering, and model deployment, evaluation, and retraining.
Pecan’s predictive analytics platform is one such example, and here are some ways our AutoML process prevents mistakes from occurring in your predictive models:
- Pre-configured models that guide your data objectives and SQL queries
- Automated data cleansing, preparation, and validation prior to the modeling process
- Automatic processes that detect and deal with imbalance data sets, thus preventing inaccurate model performance
- Automatic monitoring of model performance to ensure accuracy of predictions and suggest adjustments over time
The end result is that you can build, deploy, and scale predictive models for your organization. And you can do so without the expertise of a highly trained team of data scientists. All you need is a data analyst (or even a colleague with data skills) who can perform basic data functions so the model knows how to ingest and interpret your data – automation will take care of the rest.
If you’d like to learn more about Pecan and how our predictive analytics platform solves real-word business problems with superhuman accuracy, be sure to book a demo or sign up for your free account.

Team Pecan is what happens when you put a bunch of data geeks in a room and tell them to make machine learning suck less. We’ve built models, broken models, fixed models, and occasionally questioned our life choices at 2am debugging feature pipelines. Now we write about it so you don’t have to learn the hard way. Think of us as your slightly unhinged data science friends who actually want you to succeed.

















